Start with an ordinary support classifier
The example lives in llmci-cli/llmci-testbed, a public repository with several small LLM-powered services. This one routes support tickets into hardware, billing, account, software, or general.
It is a useful CI example because the output is compact, user-visible, and easy to score. If billing tickets fall through to general, the product got worse, even if the app still returns a valid category.
services/ticket-classifier/app/classifier.py
services/ticket-classifier/app/prompts/classify.txt
services/ticket-classifier/evals/tickets.jsonl
services/ticket-classifier/llmci-prompt.yaml
services/ticket-classifier/scripts/run_prompt.py
.github/workflows/llmci.ymlThe regression is one prompt rule
The original prompt treats payments, subscriptions, charges, and refunds as billing. A pull request tries to make that rule more precise, but it narrows the category so far that plan-change and discount-code tickets fall out of it.
@@ Rules
"hardware" = physical devices, peripherals, connectivity issues
- "billing" = payments, subscriptions, charges, refunds
+ "billing" = invoice documents and payment method updates only;
+ do not use for subscription changes, refunds, cancellations,
+ discounts, renewals, or price disputes
"account" = login, passwords, profile, permissions
"software" = apps, crashes, bugs, updates
"general" = anything that doesn't clearly fit above
+
+If a ticket mentions both money and a product issue, prefer the product issue category.In isolation, the change looks reasonable. It is trying to reduce ambiguous billing routes. In behavior, it breaks plan-upgrade and discount-code tickets that should still route to billing.
The eval runs the real classifier
The eval does not inspect the prompt in isolation. It runs the same classifier wrapper the app uses: read the prompt template, fill in the ticket, and call a model through LiteLLM. The default is openai/gpt-4o-mini, but the same wrapper can point at any LiteLLM-supported provider through CLASSIFIER_MODEL.
prompt_template = PROMPT_PATH.read_text()
prompt = prompt_template.replace("{input}", text)
model = os.environ.get("CLASSIFIER_MODEL", "openai/gpt-4o-mini")
category = complete(prompt, model=model).strip().lower()
if category not in CATEGORY_KEYWORDS:
return "general", 0
return category, CONFIDENCE_THRESHOLDllmci does not need to know anything special about that code. It only needs a command that accepts an input file and writes an output file.
data = json.loads(Path(args.input).read_text())
category, _ = classify_core(data["input"])
Path(args.output).write_text(json.dumps({"output": category}))The eval is small on purpose
The dataset is not a giant benchmark. It is a focused set of normal support tickets that should keep working across prompt edits.
{"input": "Can I upgrade from the Basic to Pro plan mid-cycle...",
"expected": "billing"}
{"input": "I was given a 20% discount code but it says expired...",
"expected": "billing"}
{"input": "I received an invoice for $299 but my plan is supposed to be $199...",
"expected": "billing"}These are the kinds of examples the prompt diff endangers. If the model stops treating plan changes and discount problems as billing, the output still looks valid; it is just wrong.
The config turns it into a CI gate
The llmci config ties the wrapper and dataset together, then sets two thresholds: accuracy must stay at or above 0.90, and macro F1 must stay at or above 0.85.
target:
command: "python3 scripts/run_prompt.py --input {input_file} --output {output_file}"
evals:
- name: prompt-classification
level: prompt
dataset: ./evals/tickets.jsonl
judge: exact_match
metrics:
- name: accuracy
threshold: 0.90
mode: absolute
- name: f1_macro
threshold: 0.85
mode: absoluteFor a real-model run, CI only needs the same pieces the application already needs: provider credentials, a model name, and the normal pull request comparison.
- name: Run focused classifier prompt eval
working-directory: services/ticket-classifier
env:
MOCK_LLM: "0"
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
CLASSIFIER_MODEL: openai/gpt-4o-mini
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: llmci run --config llmci-prompt.yaml --compare-to=origin/mainThe report explains the failure
When the prompt change runs through the gate, llmci reports both the aggregate drop and the concrete tickets that changed. The public focused testbed PR applies this exact prompt regression and adds a dedicated workflow job for ticket-classifier / llmci-prompt.yaml.
Above the configured 0.90 quality floor.
Below the configured 0.85 threshold.
Failed examples attached to the review comment.
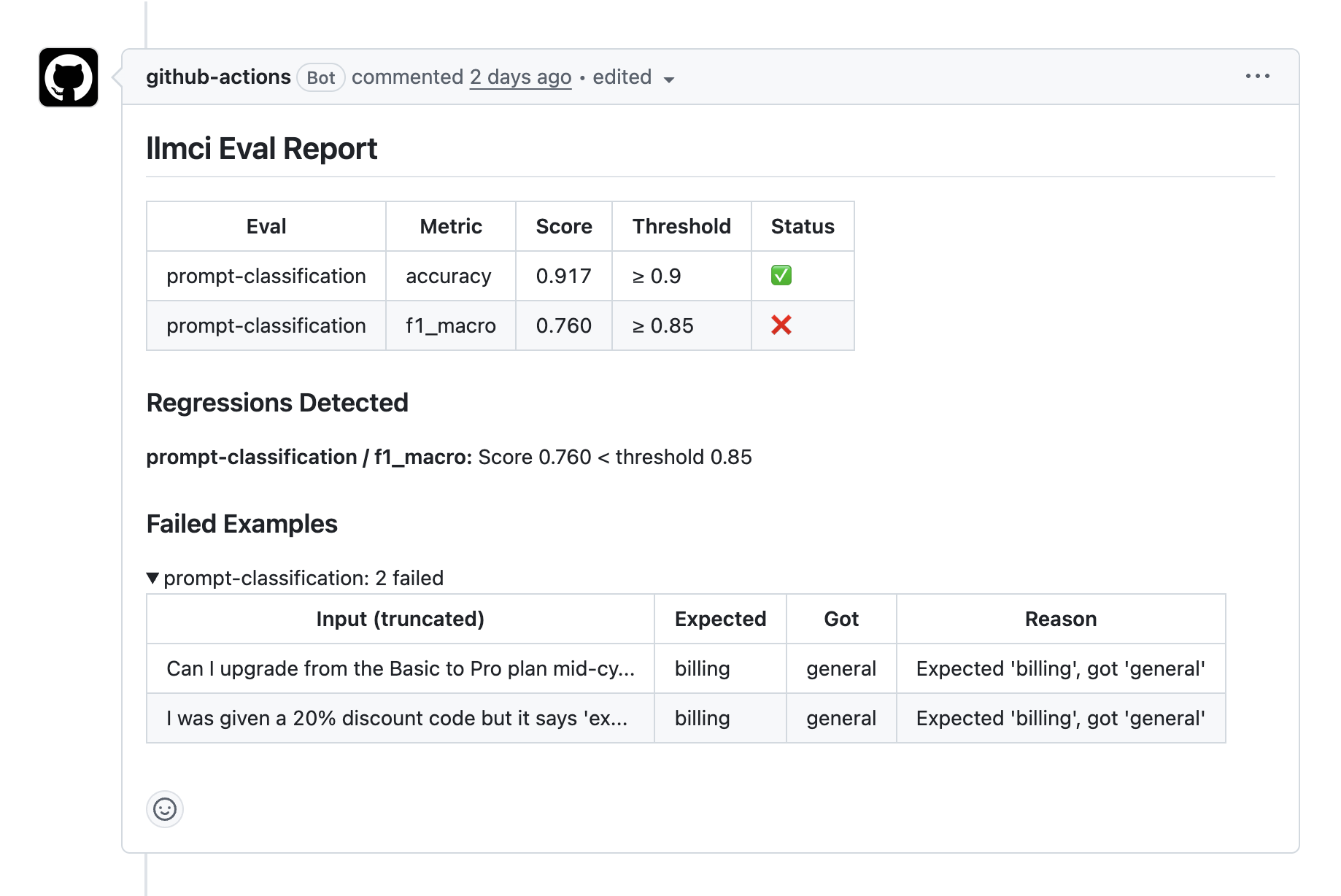
The failed examples make the regression obvious. Billing tickets that should route to the billing queue are now falling through to general.
What review alone can miss
A reviewer can read the prompt diff and still miss how it changes model behavior across the examples that matter. llmci turns that question into a repeatable gate.
- It runs the model-backed path. The target command calls the same classifier wrapper used by the app.
- It reports product-level behavior. The failure is framed as macro F1, with classifier accuracy shown alongside it.
- It gives examples. Reviewers see which tickets changed and what they changed into.
- It fits CI. The result is a normal pass/fail check and a pull request comment.
The lesson is not that prompts are uniquely fragile. The lesson is that LLM app regressions often look like ordinary application changes until you run behavioral checks against the model-backed product boundary.
Try it yourself
Open the testbed repository, inspect the ticket classifier service, and apply the prompt diff above on a branch. The smallest useful version of this pattern is:
- Commit representative examples in
evals/*.jsonl. - Add a target command that runs your model-backed wrapper.
- Set one or two thresholds your team actually trusts.
- Run
llmci run --config llmci-prompt.yaml --compare-to=origin/mainon pull requests.